S12 - Model Source and Checkpoint
Table of contents
Source Code
Note
The source code will be provided as a git repository in the final version. In the meantime, you can download the source code as a zip file.
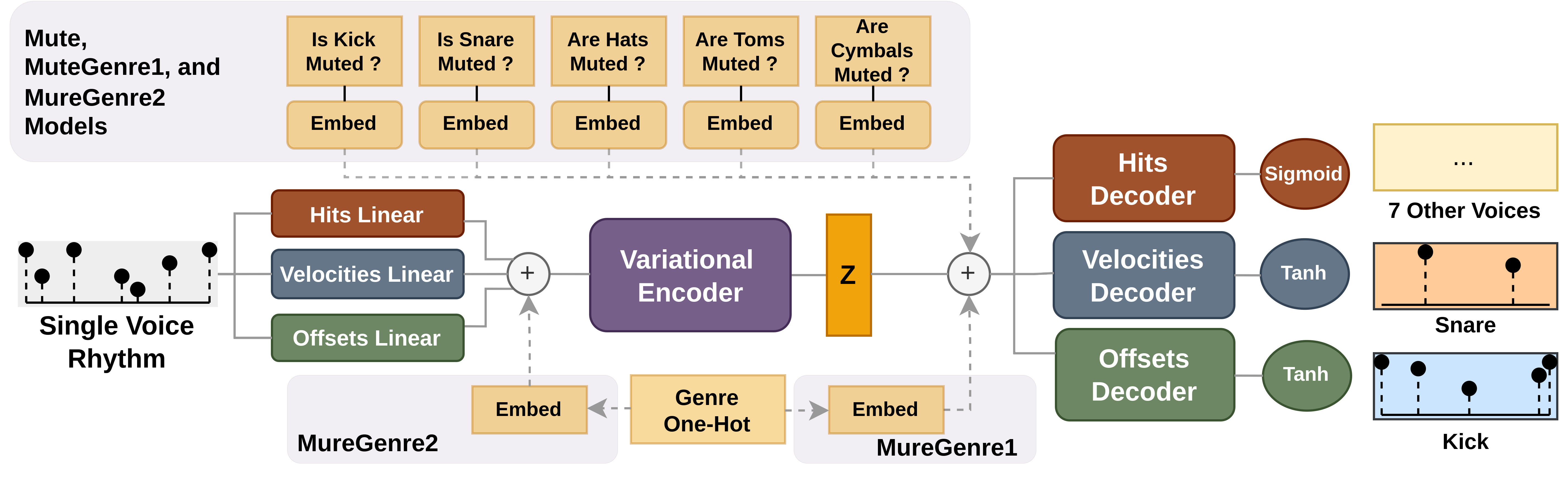
Note This section will be dedicated to the trained generative models. To access and read more about the
GenreClassifiermodel, refer to here
Architecture
Encoder:
n_layers: 3
n_heads: 4
embedding_dim: 128
ffn_dim: 512
Latent:
latent_dim: 128
Decoder:
n_layers: 7
n_heads: 8
embedding_dim: 16
ffn_dim: 16
Download Trained Models
Base Models
Mute Models
MuteGenre1 Models
MuteGenre2 Models
API
1. Loading Trained Models
First, define a generalised function to load a model from a given path. The function takes the path to the model, the model class, and the parameters of the model as input. The function returns the loaded model.
import torch
from model import BaseVAE, MuteVAE, MuteGenreLatentVAE, MuteLatentGenreInputVAE
def load_model(model_path, model_class, params_dict=None, is_evaluating=True, device=None):
try:
if device is not None:
loaded_dict = torch.load(model_path, map_location=device)
else:
loaded_dict = torch.load(model_path)
except:
loaded_dict = torch.load(model_path, map_location=torch.device('cpu'))
if params_dict is None:
if 'params' in loaded_dict:
params_dict = loaded_dict['params']
else:
raise Exception(f"Could not instantiate model as params_dict is not found. "
f"Please provide a params_dict either as a json path or as a dictionary")
if isinstance(params_dict, str):
import json
with open(params_dict, 'r') as f:
params_dict = json.load(f)
model = model_class(params_dict)
model.load_state_dict(loaded_dict["model_state_dict"])
if is_evaluating:
model.eval()
return model
Subsequently, you can load the model using the function as follows:
model_base = load_model("path/to/base_vae_beta_0_2.pth", BaseVAE)
model_mute = load_model("path/to/mute_vae_beta_0_2.pth", MuteVAE)
model_mute_genre1 = load_model("path/to/mute_genre_latent_vae_beta_0_2.pth", MuteGenreLatentVAE)
model_mute_genre2 = load_model("path/to/mute_latent_genre_input_vae_beta_0_2.pth", MuteLatentGenreInputVAE)
2. One pass groove to drum generation
Prepare Necessary Imports
First, prepare the groove input (shape: Batch, 32, 3)
groove_hits = torch.tensor([1, 0, 0, 0] * 8, dtype=torch.float).view(1, 32, 1).float()
groove_velocities = torch.rand((1, 32, 1)) * groove_hits # values between 0 and 1 at hits == 1
groove_offsets = (torch.rand((1, 32, 1)) - 0.5) * groove_hits # values between -0.5 and 0.5 at hits == 1
input_groove = torch.cat([groove_hits, groove_velocities, groove_offsets], dim=-1)
If you’re using Mute, MuteGenre1, MuteGenre2 models, you need to prepare controls as well.
# 0 for unmuted, 1 for muted
kick_is_muted = torch.tensor([[0]], dtype=torch.long)
snare_is_muted = torch.tensor([[0]], dtype=torch.long)
hat_is_muted = torch.tensor([[0]], dtype=torch.long)
tom_is_muted = torch.tensor([[0]], dtype=torch.long)
cymbal_is_muted = torch.tensor([[0]], dtype=torch.long)
# genre controls
# use 0 to 8 for ['Afro', 'Disco', 'Funk', 'Hip-Hop/R&B/Soul', 'Jazz', 'Latin', 'Pop', 'Reggae', 'Rock']
genre_ix = torch.tensor([[3]], dtype=torch.long) # Hip-Hop/R&B/Soul
Inference
Then, use predict to quickly forward the input groove through the model and post-process the output.
# simple prediction
hvo, latent_z = model_base.predict(input_groove)
hvo, latent_z = model_mute.predict(input_groove, kick_is_muted, snare_is_muted, hat_is_muted, tom_is_muted, cymbal_is_muted)
hvo, latent_z = model_mute_genre1.predict(input_groove, genre_ix, kick_is_muted, snare_is_muted, hat_is_muted, tom_is_muted, cymbal_is_muted)
hvo, latent_z = model_mute_genre2.predict(input_groove, genre_ix, kick_is_muted, snare_is_muted, hat_is_muted, tom_is_muted, cymbal_is_muted)
or use forward method for more control over the output.
# forward pass
h_logits, v_logits, o_logits, mu, log_var, latent_z = model_base.forward(input_groove)
h_logits, v_logits, o_logits, mu, log_var, latent_z = model_mute.forward(input_groove, kick_is_muted, snare_is_muted, hat_is_muted, tom_is_muted, cymbal_is_muted)
h_logits, v_logits, o_logits, mu, log_var, latent_z = model_mute_genre1.forward(input_groove, genre_ix, kick_is_muted, snare_is_muted, hat_is_muted, tom_is_muted, cymbal_is_muted)
h_logits, v_logits, o_logits, mu, log_var, latent_z = model_mute_genre2.forward(input_groove, genre_ix, kick_is_muted, snare_is_muted, hat_is_muted, tom_is_muted, cymbal_is_muted)
# activate outputs
hits = torch.sigmoid(h_logits)
velocities = torch.tanh(v_logits) + 0.5 # Make sure you use 0.5
offsets = torch.tanh(o_logits)
3. Encoding/Decoding
Prepare inputs as shown above, then:
# Encoding
mu, log_var, latent_z, memory = model_base.encodeLatent(input_groove) # memory is prior to mu and log_var
mu, log_var, latent_z, memory = model_mute.encodeLatent(input_groove)
mu, log_var, latent_z, memory = model_mute_genre1.encodeLatent(input_groove)
mu, log_var, latent_z, memory = model_mute_genre2.encodeLatent(input_groove, genre_ix) # genre_ix is passed to the encoder
# Decoding
h_logits, v_logits, o_logits, hvo_logits = model_base.decode(latent_z)
h_logits, v_logits, o_logits, hvo_logits = model_mute.decode(latent_z, kick_is_muted, snare_is_muted, hat_is_muted, tom_is_muted, cymbal_is_muted)
h_logits, v_logits, o_logits, hvo_logits = model_mute_genre1.decode(latent_z, genre_ix, kick_is_muted, snare_is_muted, hat_is_muted, tom_is_muted, cymbal_is_muted) # genre passed to the decoder
h_logits, v_logits, o_logits, hvo_logits = model_mute_genre2.decode(latent_z, kick_is_muted, snare_is_muted, hat_is_muted, tom_is_muted, cymbal_is_muted)
# activate outputs
hits = torch.sigmoid(h_logits)
velocities = torch.tanh(v_logits) + 0.5 # Make sure you use 0.5
offsets = torch.tanh(o_logits)
4. Random Sampling
# Random Sampling
latent_z = torch.randn(1, 128)
h_logits, v_logits, o_logits, hvo_logits = model_base.decode(latent_z)
h_logits, v_logits, o_logits, hvo_logits = model_mute.decode(latent_z, kick_is_muted, snare_is_muted, hat_is_muted, tom_is_muted, cymbal_is_muted)
h_logits, v_logits, o_logits, hvo_logits = model_mute_genre1.decode(latent_z, genre_ix, kick_is_muted, snare_is_muted, hat_is_muted, tom_is_muted, cymbal_is_muted)
h_logits, v_logits, o_logits, hvo_logits = model_mute_genre2.decode(latent_z, kick_is_muted, snare_is_muted, hat_is_muted, tom_is_muted, cymbal_is_muted)